Mastering SQL: Top Interview Questions and Answers
Prepare for your SQL interview with this comprehensive guide

1. What is the purpose of the GROUP BY clause in SQL? Provide an example.
The GROUP BY clause in SQL groups rows with the same values in specified columns into summary rows. It is used with aggregate functions like COUNT(), SUM(), and AVG() to perform calculations on each group, helping to summarize data.
Example: Write a SQL query to get the total sales amount for each salesperson.
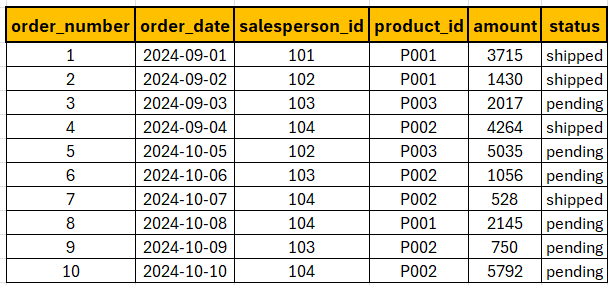
SELECT salesperson_id, SUM(amount) AS total_sales
FROM orders
GROUP BY salesperson_id;
2. Explain the purpose of the ORDER BY clause in SQL queries and provide examples.
The ORDER BY clause in SQL is used to sort the results of a query. We can sort the data in ascending (ASC) or descending (DESC) order based on one or more columns.
For example,
SELECT * FROM employees
ORDER BY salary DESC;The above will list employees from highest to lowest salary.
SELECT * FROM products
ORDER BY product_name ASC;This will list products alphabetically.
The ORDER BY clause helps arrange the data in a way that makes it easier to analyze and understand.
3. Discuss the role of the WHERE clause in SQL queries and provide examples of its usage.
The WHERE clause filters rows based on specified conditions, allowing us to retrieve only relevant data from a query. Without it, a query returns all records from the table.
The WHERE clause can be used with other SQL clauses like SELECT, UPDATE, and DELETE to target specific records. It supports logical operators (AND, OR, NOT) for combining multiple conditions and utilizes comparison operators (e.g., =, <, >, <=, >=, <>) for precise data filtering.
4. What is the difference between where and having clause in sql?
The WHERE and HAVING clauses in SQL are both used to filter data, but at different stages.
WHERE filters rows before any grouping or aggregation happens, applying conditions directly to individual records.
HAVING, on the other hand, filters data after the GROUP BY operation and is used to apply conditions to aggregated results, like counts or averages.
WHERE is for filtering individual rows, while HAVING is for filtering groups of rows after they’ve been aggregated.
5. Explain the purpose of the LIKE operator in SQL and provide examples of its usage.
The LIKE operator is used to search for a pattern in a column. It helps find values that match a specific pattern, using special symbols called wildcards. The percent sign (%) represents any number of characters, and the underscore (_) represents a single character.
Example:
SELECT * FROM customers
WHERE name LIKE 'A%'This will find all customers whose names start with “A”.
SELECT * FROM products
WHERE product_name LIKE '%phone%'This will return all products with “phone” in their name.
The LIKE operator is helpful when we want to find partial matches instead of exact ones.
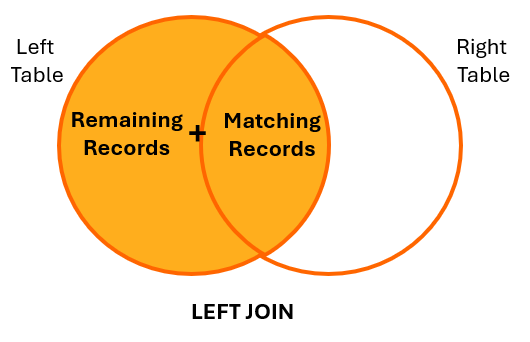
6. a) Explain the difference between an INNER JOIN and a LEFT JOIN with examples.
An INNER JOIN returns only the matching rows from both tables. If there is no match, the rows are excluded from the result set. We need INNER JOIN when we want to retrieve records that have corresponding entries in both tables.

A LEFT JOIN retrieves all rows from the left table and the matching rows from the right table. If there’s no match, we get NULL for the right table’s columns. We use a LEFT JOIN when we want to retrieve all records from the left table, even if some do not have corresponding entries in the right table.
6. b) Describe a scenario where you would use a self-join in SQL and explain its benefits.
A self-join in SQL is used when we need to join a table to itself, often to compare rows within the same table.
A common scenario is when we have a hierarchical structure in the data, such as an employee table where each employee has a manager who is also an employee. For example, in an Employees table with columns like employee_id, name, and manager_id (where manager_id refers to another employee_id), a self-join allows us to match each employee with their respective manager.
The benefit of a self-join is that it enables us to retrieve related data from the same table without needing to duplicate the information in a different table. It is especially useful in hierarchical or relational data structures, where entities are related to other instances of the same entity.
7. How do you use CASE statement in SQL?
The CASE function in MySQL works like an if-then-else statement, evaluating conditions and returning the value of the first true condition. If no conditions match, it returns the value in the ELSE clause (or NULL if there is no ELSE). It can be used in SELECT, WHERE, and ORDER BY clauses.
Assume we have a table called employees:

Now we want to categorize employees based on their performance scores.
SELECT
EmployeeID,
Name,
PerformanceScore,
CASE
WHEN performance_score >= 90 THEN 'Excellent'
WHEN performance_score >= 75 THEN 'Good'
WHEN performance_score >= 50 THEN 'Average'
ELSE 'Poor'
END AS Rating
FROM employees;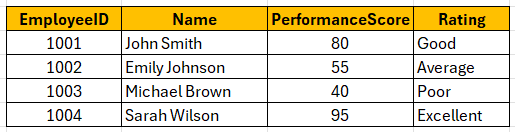
8. Discuss the differences between the CHAR and VARCHAR data types in SQL.
CHAR and VARCHAR are both used to store text, but they handle storage differently.
CHAR is a fixed-length type, meaning it always reserves the same amount of space, even if the string is shorter, padding with spaces if needed.
VARCHAR is variable-length, using only as much space as the actual text, plus a small amount for storing the length. VARCHAR is more efficient for varying text lengths, while CHAR is better for fixed-length data.
9. How can you delete duplicate rows in a SQL Table?
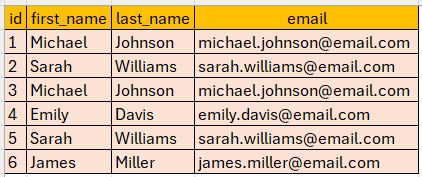
a) Removing Duplicate Rows in MySQL Using ROW_NUMBER():
The following SQL query removes duplicate records from the employee table by using the ROW_NUMBER() function to identify and delete rows with the same first_name, last_name, and email, keeping only the first occurrence based on the id order (smallest id).
DELETE FROM employee
WHERE id IN (
SELECT id FROM (
SELECT *, ROW_NUMBER()
OVER(PARTITION BY first_name, last_name, email ORDER BY id ) AS rn
FROM employee) a
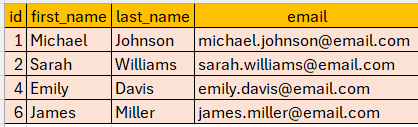
WHERE rn > 1 );b) Removing Duplicate Records in MySQL Using Self Join:
The following SQL query deletes duplicate rows from the employee table by joining the table with itself and comparing the id, first_name, last_name, and email columns. The query deletes the row with the higher id when there are duplicate values, effectively keeping the row with the smallest id for each group.
DELETE e1 FROM employee e1
INNER JOIN employee e2
ON e1.id > e2.id
AND e1.first_name = e2.first_name
AND e1.last_name = e2.last_name
AND e1.email = e2.email;Output:
10. What is union operator?
The UNION operator in SQL combines the results of multiple SELECT statements into one result set. It requires the same number of columns with matching data types and order. UNION automatically removes duplicate rows, returning only distinct values from the combined tables.
SELECT CustomerID, CustomerName FROM Customers_USA
UNION
SELECT CustomerID, CustomerName FROM Customers_Canada;11. Explain the difference between an aggregate function and a scalar function in SQL, with examples.
Aggregate functions work on multiple rows and return a single result, like calculating the total or average. Examples include SUM, AVG, and COUNT.
Scalar functions work on a single value or row and return a result for each row, such as changing text to uppercase or finding the length of a string. Examples are UPPER, LOWER, and LEN.
Aggregate functions summarize data, while scalar functions modify individual values.
12. a) Explain the concept of database transactions and the ACID properties.
A database transaction in MySQL is a set of one or more queries that are executed as a single unit of work. If any query in the transaction fails, the entire transaction can be rolled back, ensuring the database remains consistent and preventing invalid data from being stored.
This process ensures that a group of related operations is either fully completed or not executed at all, maintaining data integrity and consistency in the database.

The ACID properties of transactions:
ACID is an acronym for the four properties that define a reliable database transaction:
- Atomicity: A transaction is treated as a single unit —either all changes are applied, or none. If any part fails, the entire transaction is rolled back to its original state.
- Consistency: A transaction ensures the database moves from one valid state to another, preserving rules like constraints and triggers.
- Isolation: Transactions are processed independently, ensuring they don’t interfere with each other, and intermediate results are not visible until completion.
- Durability: Once committed, changes are permanent and will not be lost, even in case of a system crash.

12. b) How do you handle transactions in sql?
- Start the transaction using START TRANSACTION.
- Execute the SQL queries.
- If everything is correct, commit the changes using COMMIT.
- If there’s an error or issue, use ROLLBACK to undo the changes and restore the database to its prior state.
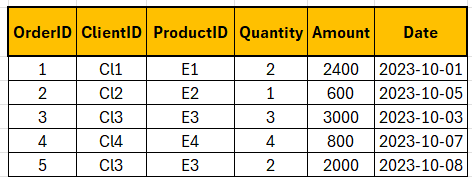

START TRANSACTION;
-- Insert Orders
INSERT INTO Orders (OrderID, ClientID, ProductID, Quantity, Amount, Date)
VALUES (6, 'Cl2', 'E3', 1, 1000.00, '2023-12-10');
-- Update the stock
UPDATE Products
SET ItemsInStock = ItemsInStock - 1
WHERE ProductID = 'E3';
SELECT * FROM Orders;
SELECT * FROM Products;
-- Commit the transaction to apply changes permanently
COMMIT;
-- If any error occurs, then instead of commit execute rollback
-- ROLLBACK;12. c) Discuss the role of the COMMIT and ROLLBACK statements in SQL transactions.
The COMMIT and ROLLBACK statements are crucial for managing SQL transactions and ensuring data integrity:
- COMMIT finalizes a transaction, making all changes permanent in the database. It signals successful completion and cannot be undone.
- ROLLBACK undoes all changes made during the transaction, restoring the database to its previous state. It is used when an error occurs, ensuring no partial or inconsistent data is saved.
They ensure that transactions are either fully completed or fully reverted.
13. Describe the benefits of using subqueries in SQL and provide a scenario where they would be useful.
Subqueries allow us to run one query inside another, making it easier to handle more complex tasks. They break down a large query into smaller, simpler parts, making it easier to understand and manage.
Subqueries are useful when we need to calculate something first, like an average or maximum, and then use that result in the main query. For example, to find employees who earn more than the average salary, we can use a subquery to calculate the average salary and then filter employees based on that value.
SELECT employee_name FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);14. What is an Index and why is it important?
An index is a tool that helps the database find and retrieve data faster. It works like an index in a book, allowing the database to quickly locate specific rows based on certain columns, without having to search through the entire table.
Indexes are important because they make queries run faster, especially on large tables. However, they can slow down write operations (like adding or updating data) since the index also needs to be updated. So, it is important to use indexes on columns that are frequently searched or filtered.
15. a) Discuss the differences between a clustered and non-clustered index in SQL.
When we create any index, there will be a balanced tree (B-tree) structure.
Clustered Index
A clustered index determines the physical order of the data in the table. The rows are stored in the order of the indexed column. There can only be one clustered index per table because the data rows themselves can only be sorted in one way.
In a clustered index, the leaf nodes of the B-tree contain the actual data pages. In SQL Server, if a primary key is defined and no clustered index is specified, a clustered index is created by default on that key.
Clustered indexes are generally faster for range queries and retrievals of large data sets since the data is physically sorted. They do not require additional storage for the index itself, as the data is stored in the index structure.
Non-clustered Index
A non-clustered index does not sort the physical data in the table. Instead, it creates a separate structure to store the index. This is similar to a book index, which lists topics separately with pointers to the actual pages. You can have multiple non-clustered indexes on a table.
In a non-clustered index, the leaf nodes point to the clustered index or directly to the data rows if there is no clustered index. This means it relies on the clustered index to locate the actual data. Since non-clustered indexes are stored separately from the main table, they require additional storage space.
b) Explain how a clustered index works.
A clustered index determines the physical order of data rows in a table. The data rows themselves are sorted and stored in the same order as the indexed column(s). This means that when a clustered index is created on a table, the rows are reordered on the disk according to the values of the indexed column. As a result, a table can only have one clustered index, because the data can only be physically sorted in one way. When we query the table using the clustered index, the database can directly access the data without needing an additional lookup, making it faster for certain types of queries.
16. Explain the role of the SELECT INTO statement in SQL and provide examples of its usage.
The SELECT INTO statement is used to create a new table and copy data into it from an existing table or query. It combines creating a new table and inserting data into it in one step, so we do not need to create the table separately first.
It is useful when you want to create a table based on certain conditions, like copying only employees with high salaries into a new table.
SELECT * INTO high_salary_employees
FROM employees
WHERE salary > 50000;This makes it easy to work with subsets of data or make backups.
17. What is a Constraint?
A constraint in a database is a rule or limit applied to a table’s columns to ensure data integrity and accuracy. Examples of constraints include NOT NULL (which ensures a column cannot have empty values) and AUTO INCREMENT (which automatically generates unique values for a column, typically used for primary keys). Constraints help maintain the quality and consistency of the data stored in a database.
18. What is the difference between primary key and unique key?
Primary Key:
The PRIMARY KEY uniquely identifies each record in a table, ensuring that the values in the designated column are unique and not NULL. This constraint is essential for maintaining data integrity. A table can have only one primary key, and if more than one is defined, an error will occur.
Unique Key:
The UNIQUE key ensures that all values in a column (or set of columns) are distinct, preventing duplicate entries. Unlike the primary key, a unique key can contain NULL values, and a table can have multiple unique keys. If you try to insert a duplicate value into a column with a unique constraint, an error will occur.
19. a) Describe the importance of data integrity constraints such as NOT NULL, UNIQUE, and CHECK constraints in SQL databases.
Data integrity constraints ensure accuracy and consistency in SQL databases.
- NOT NULL ensures a column cannot have NULL values, requiring valid data for every row. However, empty strings or zero values can still be inserted depending on the data type.
- UNIQUE prevents duplicate values in a column, ensuring distinct entries, such as for email addresses or user IDs.
- CHECK enforces specific conditions on column values (e.g., range limits or valid data), throwing an error if violated during insert or update operations.
19. b) What is a Candidate key?
A candidate key is a key or set of keys that can uniquely identify each record in a table. It is a potential primary key.
A table can have multiple candidate keys, and one of them is chosen as the primary key. The others are called alternate keys. All candidate keys must have unique values for every record and cannot contain NULL values.
20. Explain the difference between TRUNCATE, DELETE, and DROP.
- TRUNCATE: A DDL command that removes all rows from a table but keeps its structure. It is faster than DELETE and DROP because it deletes all the records at a time without any condition. It doesn’t free the allocated space of the table.
- DELETE: A DML command that removes rows based on a condition (or all rows if no condition is provided). It is slower than TRUNCATE because it processes rows individually and supports transactions. It also doesn’t free the allocated space of the table.
- DROP: A DDL command that completely removes a table (including its data and structure) from the database. It is faster than DELETE and it completely removes the allocated space for the table from memory.
21. What is a view?
A view is a virtual table created from one or more underlying tables in MySQL. Unlike regular tables, views do not store data; instead, they dynamically retrieve it when accessed, providing a table-like interface for users. Database engineers use views for several key reasons:
- Views can create a subset of a table’s data, allowing access to only the necessary columns and rows.
- Views can combine data from multiple tables, enabling users to query specific columns from different sources in one virtual table.
- Views can help control data access by granting users permission to the view instead of the underlying tables, thereby restricting which data they can see.


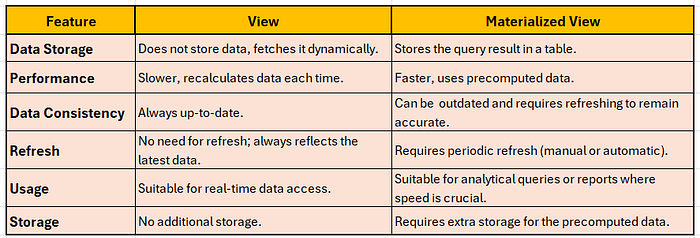
22. Describe the differences between a database view and a materialized view in SQL (PostgreSQL).
A view is a virtual table that represents the result of a stored SQL query. It does not store any data, but instead shows the results by running the query every time we access it. Views simplify complex queries, enhance security by restricting access to specific data, and allow data to be presented in a specific format. When we create a view, we give it a name, and the result of the SELECT query becomes accessible through that name.
A materialized view is a precomputed, stored version of a query result in a physical table, unlike a regular view that executes the query each time. It improves query performance by avoiding repeated calculations and reduces the load on underlying tables. The main advantages are faster queries, more efficient data access, and lower resource usage, but it requires extra storage and periodic refreshing to stay up to date.
23. a) What are stored procedures and how are they used?
Stored procedures in MySQL are a way to encapsulate SQL code into reusable, pre-defined blocks that can be executed whenever needed. The main goal of using stored procedures is to avoid repeating the same SQL code, promoting efficiency and simplifying maintenance. By encapsulating logic in a procedure, you can call it using its name whenever required, saving time and effort.
When a stored procedure is created using the CREATE PROCEDURE statement, MySQL compiles the SQL code into an execution plan, which is then stored in the server's internal cache for optimized execution.
Example Use Case:
A business might use a stored procedure to check stock levels in their products table. The procedure is created using the CREATE PROCEDURE command, followed by the procedure name and required logic. Once created, the procedure can be invoked with the CALL command to retrieve the data.
DELIMITER $$
CREATE PROCEDURE CheckStockLevel(IN p_ProductID VARCHAR(10), OUT p_StockLevel INT)
BEGIN
SELECT ItemsInStock INTO p_StockLevel
FROM Product
WHERE ProductID = p_ProductID;
-- If no product is found, set stock level to 0
IF p_StockLevel IS NULL THEN
SET p_StockLevel = 0;
END IF;
END $$
DELIMITER ;Call the Stored Procedure:
-- Declare variable to store stock level
SET @stockLevel = 0;
-- Call the stored procedure
CALL CheckStockLevel('E1', @stockLevel);
-- Output the result
SELECT @stockLevel AS StockLevel;Notes:
- Input Parameters: Stored procedures can accept input parameters, allowing values to be passed when the procedure is called.
- Output Parameters: Unlike functions, stored procedures can return values through output parameters.
- If no data is found in the table, a stored procedure can be designed to return NULL or handle the empty state as needed.
23. b) Discuss the advantages and disadvantages of using stored procedures.
Benefits of Stored Procedures:
- Stored procedures improve database performance, management, and security by storing pre-written SQL commands that are ready to execute.
- Stored procedures can be executed multiple times, reducing redundancy and improving efficiency.
- They reduce processing time, network traffic, and resource usage by grouping commands into a single procedure.
- They allow easy access to data and enhance security by controlling access to sensitive information.
Disadvantages:
- Large or complex procedures can be difficult to manage and maintain.
- Stored procedures are database-specific, making it challenging to migrate to other systems.
- Debugging stored procedures can be harder than debugging application code, especially in large systems.
- Poorly optimized stored procedures can negatively impact performance.
- Version management can be tricky, particularly with multiple developers.
- Stored procedures are tightly coupled with the database, which can limit scalability and flexibility.
24. What is the difference between a Common Table Expression (CTE) and a Temporary Table?
A Common Table Expression (CTE) is a temporary result set used within a single query. It simplifies complex queries by breaking them into smaller, more readable parts, but it only exists during the execution of that query.
On the other hand, a Temporary Table is stored in the TempDB (a special database for temporary storage) and can hold data across multiple queries within the same session. It is automatically deleted when the session ends or the connection is closed.
CTEs are more efficient for small data sets because they are stored in memory and are faster. Temporary tables, however, are better suited for larger data sets and more complex tasks, as they can persist across multiple queries in the session.
25. What are window functions in SQL?
Window functions allow us to perform calculations across a set of rows related to the current row, without combining the rows into a single result. This lets us calculate things like running totals, rankings, and averages while keeping each row’s data separate.
Window functions operate over a window of rows, defined by PARTITION BY (to group rows) and ORDER BY (to sort them). Some common window functions are ROW_NUMBER(), RANK(), SUM(), and LEAD() etc. They make queries simpler, more efficient and faster for tasks that require complex calculations without losing individual row details.
26. How do you optimize a slow-running query?
Optimizing SELECT queries is crucial for improving database performance and ensuring efficient data retrieval. Key techniques include -
- Avoiding the use of SELECT *
- Utilizing indexes on frequently queried columns
- Avoiding functions or leading wildcards in the WHERE clause, which can prevent index usage.
- Employing INNER JOIN instead of OUTER JOIN
- Using UNION ALL instead of UNION
- Applying filters early in queries
- Replacing multiple OR conditions with IN
- Minimizing subqueries
- Using Common Table Expressions (CTEs)
- Using LIMIT
27. Describe the concept of normalization forms (1NF, 2NF, 3NF) and why they are important in database design.
Normalization forms (1NF, 2NF, and 3NF) are rules in database design that help organize data and reduce repetition.
1NF (First Normal Form) makes sure each column has only single, indivisible values, with no repeating groups or arrays. This helps keep the data clean and easy to manage.
2NF (Second Normal Form) builds on 1NF by ensuring that all columns depend on the full primary key, not just part of it. This removes partial dependencies in tables with composite keys.
3NF (Third Normal Form) improves the design further by making sure non-key columns depend only on the primary key, not on other non-key columns. This removes unnecessary relationships between non-key columns.
Normalization forms are important in database design because they help organize data, reduce repetition, and keep the data accurate. 1NF ensures each column has only single, indivisible values and no repeating groups. 2NF removes partial dependencies for composite keys. 3NF makes sure non-key data depends only on the primary key, not on other data. Following these rules makes databases easier to maintain, less prone to mistakes, and faster for querying and updating.
28. Explain the concepts of Sharding in SQL?
Sharding is a method of splitting large databases into smaller, more manageable pieces called shards. Each shard is stored on a separate server, which helps improve performance and scalability by spreading the load across multiple machines. Sharding is useful for large databases where a single server can’t handle the data or traffic. For example, in an e-commerce app, customer orders can be split into shards by region or time period, allowing faster queries and reducing system overload.